Identifying Likely Exoplanet Host Stars from Stellar Elemental Abundances
Utilizing Extreme Gradient Boosting I train a model to estimate the likelihood of a star system hosting one or more exoplanets based on current exoplanet data and the stellar abundances of various elements using the Hypatia Catalog
PROJECTS
3/27/20247 min read
Exoplanets are valuable scientific targets which can help us improve models of solar system formation and aid in the ongoing search for life beyond Earth. You might intuit that the elements present in a given system affect the types of celestial bodies that can form there. The presence of specific elements in a solar neighborhood significantly influences the development and progression of the system. Specifically, positive correlation between the abundance of key elements and the presence of giant exoplanets has been found and initial work to employ machine learning in the identification of likely host stars which have all the requisite ingredients for planetary formation (Hinkel et al. 2019).


Figure 1. visualization of the evolution of a stellar system, Image credit: NASA
The search for exoplanets is continuous with 5,602 confirmed exoplanets at time of writing (NASA Exoplanet Archive), but telescope time remains a bottleneck for exoplanet hunters. This writeup, undertaken as the final week research project for a course in the application of machine learning for physics follows in the footsteps of Hinkel's previous work but leverages the expanded Hypatia catalog. The star catalog has nearly doubled in size since the team's original publication, presenting the opportunity for an updated model to potentially yield new insights. Like Hinkel, I train a model to predict the likelihood that a given star system hosts one or more exoplanets and make observations about trends in planetary formation based on current data.
A key challenge in the project lies in the unknown ground truth regarding exoplanet distribution and characteristics. While the presence of an exoplanet can be confirmed within a system, a true negative result cannot be confirmed. In other words, we can't rule out the possibility that a system in fact has an exoplanet which we could not detect. Further, the supervised model's learning is based on data from confirmed exoplanets. However, these confirmed exoplanets are subject to inherent biases stemming from our current search and detection methodologies, which may not accurately reflect the broader realities of planetary formation. This discrepancy potentially complicates the learning process for the model, as it may be trained on data that does not fully represent the underlying patterns of exoplanet existence. This project then represents an initial scheme for classification which should continue to be updated as we gather more data, and develop methodologies to gather data that is increasingly representative of the distributions of stellar systems throughout the galaxy.
The project obtained detailed data on stars and their elemental abundances, sourced from the Hypatia Catalog. Collection and analysis of stellar spectra sets the limit on the amount of data which can be obtained for this project. To date, the Hypatia Catalog has data on 11,160 stars, 102 elements and species, and a total of 404,715 abundance measurements.
The catalog represents a comprehensive dataset, including measurements of stellar elemental abundances for FGKM-type stars located within 500 parsecs of the Sun, as well as for select exoplanet-hosting stars irrespective of their distance.
Astrophysically speaking, certain key elements are of interest in the context of planetary formation:
Volatiles (C, O): Essential for creating planetary atmospheres. These elements are thought to be critical for the development of environments that could potentially support life.
Lithophiles (Na, Mg, Al, Si, Ca, Sc, Ti, V, Mn, Y): Key components of rock-forming minerals.
and Siderophiles (Cr, Co, Ni, and Fe): Heavy elements that tend to alloy with iron and are predominantly found within planetary cores.
Focusing on these and removing systems for which elemental data for a key element was absent in 50% of systems or more, elemental ratios and system data was obtained for 8,868 stars systems with 1,389 confirmed exoplanets.
Explorations of feature combinations and data processing methodologies were employed systematically alongside a grid search of hyperparameters in order to train an XGBoost classifier. The task of the model is to output the probability that a given star system hosts an exoplanet which might be identified by astronomers. The model reaches an overall accuracy score of 86% in classification but struggles with consistently identifying positives correctly, and is ultimately conservative in predicting exoplanet candidates.
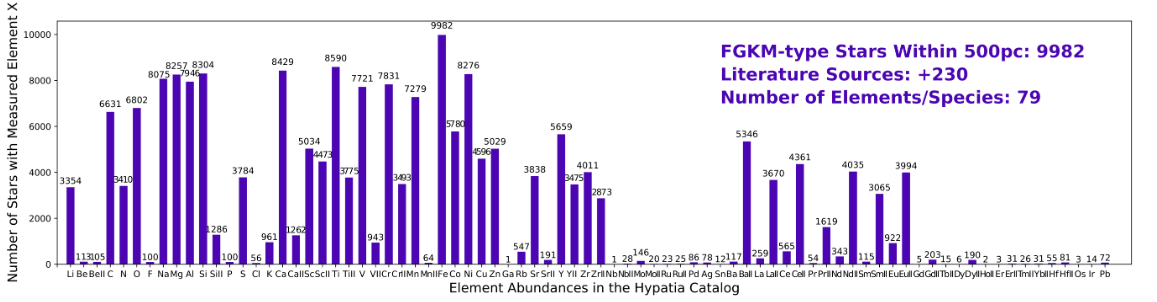
Figure 2. Hypatia Catalog and elemental abundance ratio data for measured elements. Image credit: Hypatia Catalog Database
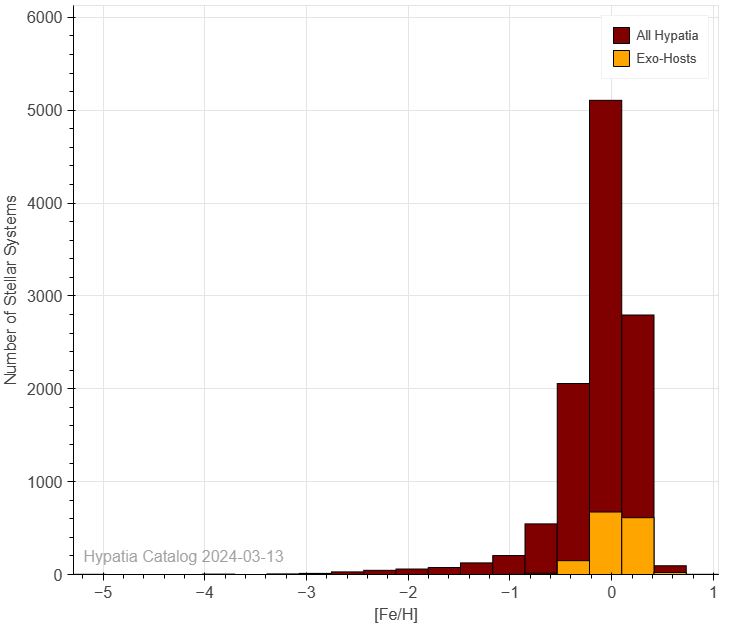
Figure 3. Star systems and systems with confirmed exoplanets binned by ratio of iron abundance.
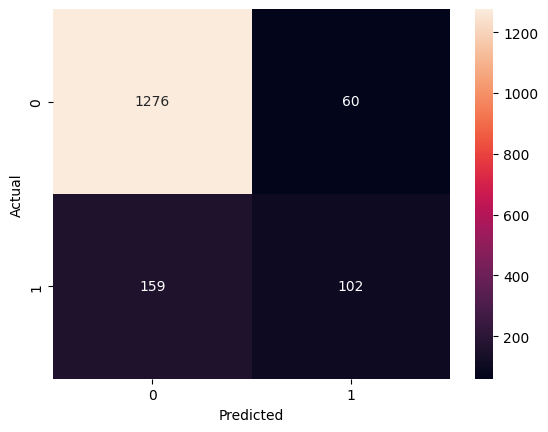
Figure 4. Exoplanet candidate classifier, confusion matrix. Here, 0 indicates no exoplanet, and 1 indicates an exoplanet
The plots below characterize how the model learned to output high probability only for those systems well within the distribution characteristic of confirmed exoplanet hosts, and give a sense of relation between stellar elemental abundances and exoplanet detection.
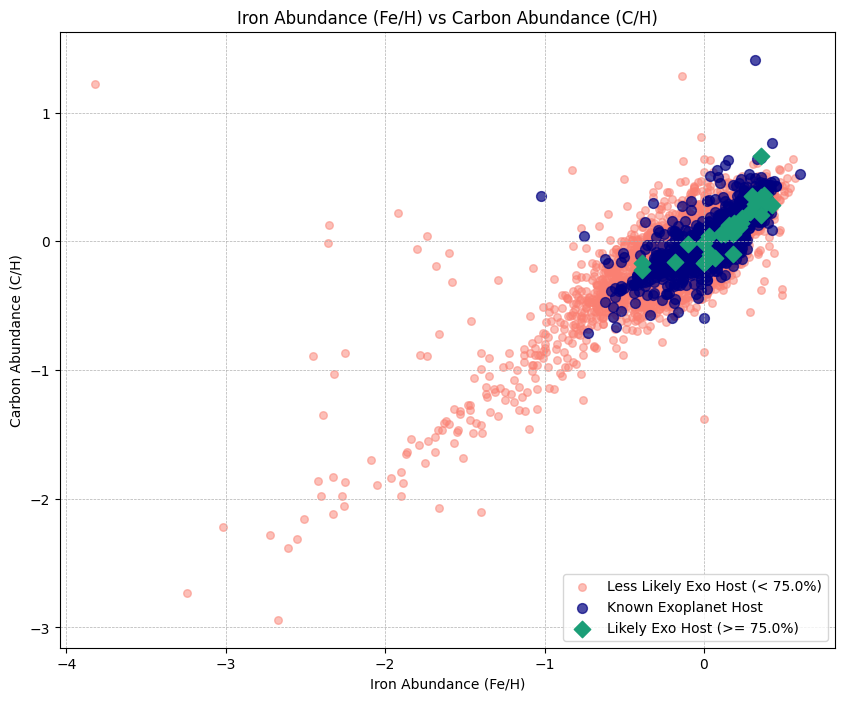
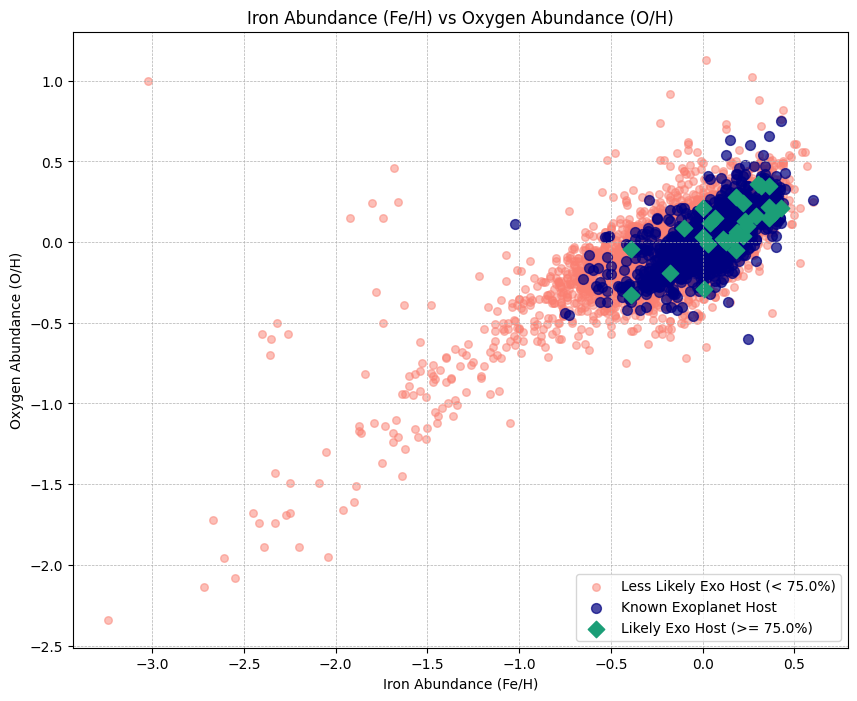
Figure 5. Stellar systems scatter plotted by elemental abundance ratios for iron and carbon.
Figure 6. Stellar systems scatter plotted by elemental abundance ratios for iron and oxygen.
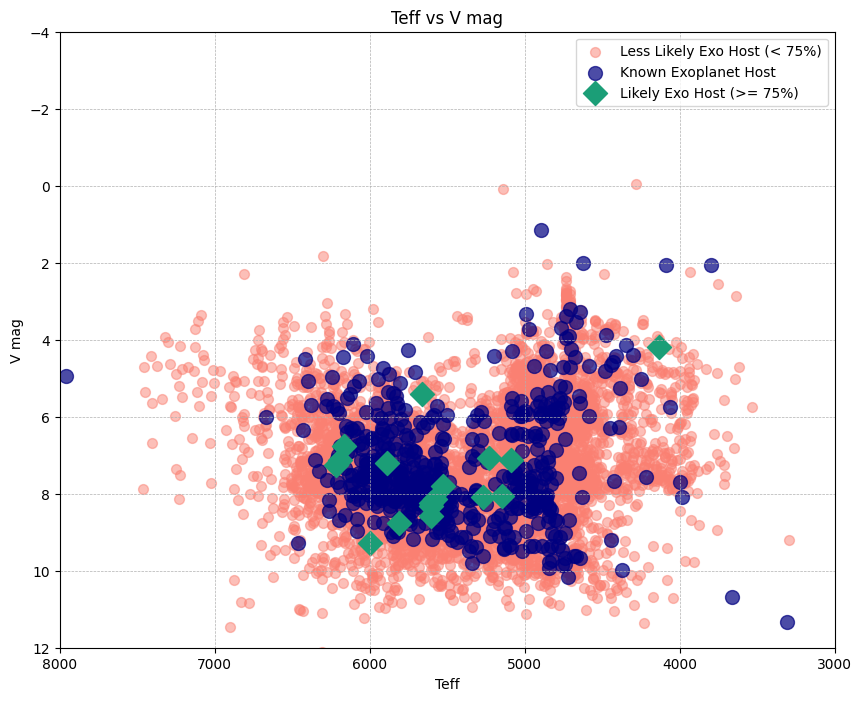
Figure 7. Stellar systems scatter plotted by V magnitude and effective temperature.
The final plot (Figure 7), plots stars on a graph of temperature vs magnitude, as in the classic Hertzsprung-Russell diagram to place stars from the Hypatia catalog in context and shows confirmed exoplanets from the catalog primarily along the FGKM subset of the main sequence.
Conclusions
Project Overview
The premise and results of this project are of some scientific interest but represent only an early foray into predicting features of stellar systems based on observational data. The significantly expanded Hyptia catalog warrants more exploration but the scope of this project was limited to keep it manageable as a week long project. Importantly, exoplanet hunting is also a young and rapidly evolving aspect of astronomy. Thousands of exoplanets have now been found but blind spots almost certainly remain as each method of exoplanet detection has its limitations and corresponding biases. The output of the model then represents a method for identifying exoplanet candidates similar to systems with previous detections, and can't speak to the true distribution of exoplanets among stellar systems throughout the galaxy. The accuracy of models such as this should increase as our exoplanet data becomes increasingly representative of our Milky Way and detection methods become less biased.
That said, some modest statements are suggested by the data. Many stars in the FGKM range (relatively similar to our own sun) host exoplanets. Based on previous detections in this range the model can identify likely exohost candidates which could make for high priority targets in near future exoplanet detection. To that end, I include a list of 29 stars, which are as yet unconfirmed to have exoplanets but are predicted by the model to have 75% or greater probability of hosting an exoplanet:
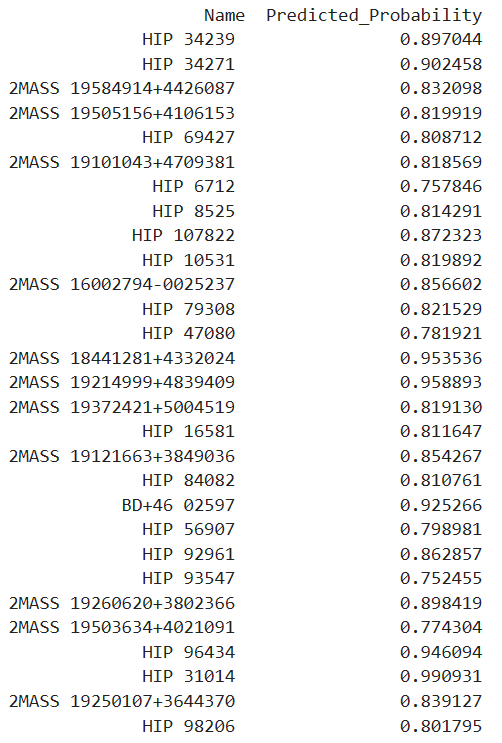
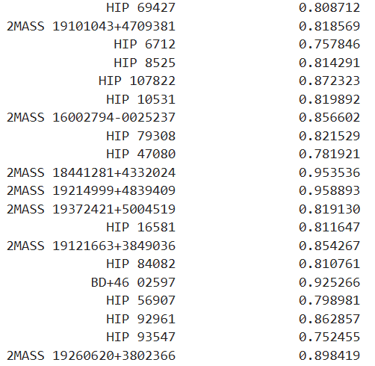
Additional Comments
This project was undertaken to get experience with XGBoost, to run an end to end ML project (from data collection to finetuning), and to get a better sense of how machine learning can be utilized in astronomy and astrophysics. I'm pleased with what was explored though many avenues for exploration yet remain if time ever permits. For this problem at least, I found that data preprocessing was very influential while tuning hyperparameters had a modest effect and played around with a mix of what I thought were good and bad ideas to develop intuitions and familiarity. Specifically, poor feature selection and failure to impute mean values where data was absent for a particular element resulted in accuracy worse than chance. Accuracy increased to around 90% when training on data that contained an equal number of each class though I ultimately opted not to use this theoretically better preforming model since doing so required tossing out a majority of the star systems with unconfirmed exoplanets. It may be the case that this improved accuracy over the dataset is because the true population of stars with exoplanets is much greater than our current exoplanet data suggests. This is plausible if not likely given limitations in our detection capabilities and the fact that we have only been searching for exoplanets since the 1990's. Still, I opted to train the model based on the entire dataset rather than speculate on what modifications would be reasonable. An experienced astrophysicist could expect to create a better training set based on additional physical considerations and estimations I think.
I think the project overall is very interesting, many more kinds of analysis seem possible and I'd like to see how models evolve as more exoplanets are found. A greater dataset could be compiled by matching up the Hypatia catalog and the Nasa Exoplanet Archive to incorporate information about the found exoplanets themselves in order to study possible correlation between elemental abundances and planet types. A dozen or more questions which are variations on how does elemental abundance or stellar feature X correlate with planet feature Y or feature common to stellar system Z seem potentially informative for astrophysical models of system formation and within reach.